1. Introduction
1.1. Problem setup
This paper addresses a new task of Few-Shot object Counting and Detection (FSCD) in crowded scenes. Given an image containing many objects of multiple classes, we seek to count and detect all objects of a target class of interest specified by a few exemplar bounding boxes in the image. To facilitate few-shot learning, in training, we are only given the supervision of few-shot object counting, i.e., dot annotations for the approximate centers of all objects and a few exemplar bounding boxes for object instances from the target class. The problem setting is depicted in Fig. 1.

Figure 1: Training and testing setting of FSOD
1.2. Prior work and their limitation
Compared to Few-shot Counting (FSC), FSCD has several advantages: (1) obtaining object bounding boxes “for free”, which is suitable for quickly annotating bounding boxes for a new object class with a few exemplar bounding boxes; (2) making the result of FSC more interpretable since bounding boxes are easier to verify than the density map. Compared to Few-shot Object Detection (FSOD) which requires bounding box annotation for all objects in the training phase of the base classes, FSCD uses significantly less supervision, i.e., only a few exemplar bounding boxes and dot annotations for all objects.
A naive approach for FSCD is to extend FamNet [1], a density-map-based approach for FSC, whose counting number is obtained by summing over the predicted density map. To extend FamNet to detect objects, one can use a regression function on top of the features extracted from the peak locations (whose density values are highest in their respective local neighborhoods), the features extracted from the exemplars, and the exemplar boxes themselves. The process of this naive approach is illustrated in Fig. 2a. However, this approach has two limitations due to: 1) the imperfection of the predicted density map, and 2) the non-discriminative peak features. In the former, the density value is high in the environment locations whose color is similar to those of the exemplars, or the density map is peak-indistinguishable when the objects are packed in a dense region as depicted in Fig. 2b. In the latter, the extracted features are trained with counting objective (not object detection) so that they cannot represent for different shapes, sizes, and orientations, as illustrated in Fig. 2c.

Figure 2: An illustration of modifying FamNet for FSOD task (a), limitation of FamNet (b), and bounding box problem of Ridge Regression (c)
1.3. Overview pipeline
First, inspired by [2] we adopt a two-stage training strategy: (1) Counting-DETR is trained to generate pseudo ground-truth (GT) bounding boxes given the annotated points of training images; (2) Counting-DETR is further fine-tuned on the generated pseudo GT bounding boxes to detect objects on test images. Second, since the generated pseudo GT bounding boxes are imperfect, we propose to estimate the uncertainty for bounding box prediction in the second stage. The estimated uncertainty regularizes learning such that lower box regression loss is incurred on the predictions with high uncertainty. The overview of Counting-DETR is illustrated in Fig. 3.
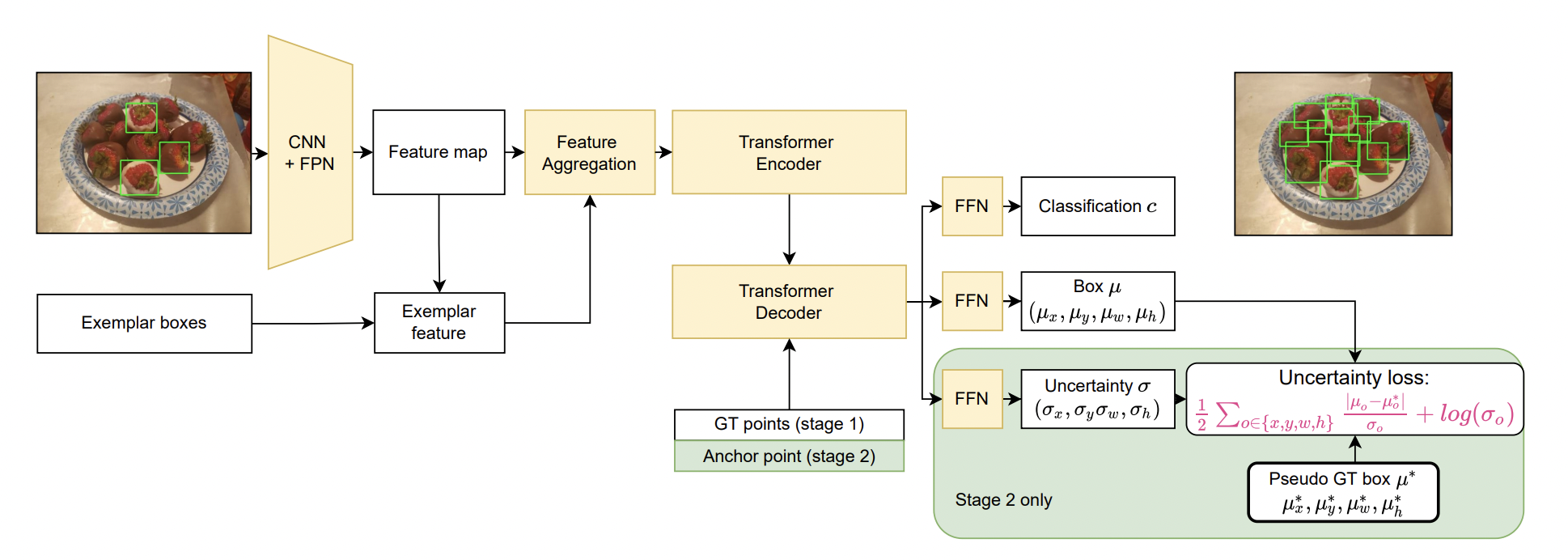
Figure 3: Overview pipeline of our proposed approach.
1.4. Contribution
The contributions of our paper are: (1) we introduce a new problem of few-shot object counting and detection (FSCD); (2) we introduce two new datasets, FSCD-147 and FSCD-LVIS; (3) we propose a two-stage training strategy to first generate pseudo GT bounding boxes from the dot annotations, then use these boxes as supervision for training our proposed few-shot object detector; and (4) we propose a new uncertainty-aware point-based few-shot object detector, taking into account the imperfection of pseudo GT bounding boxes.
2. Proposed Approach
Problem definition: In training, we are given a set of images containing multiple object categories. For each image  , a few exemplar bounding boxes
, a few exemplar bounding boxes  where
where  is the number of exemplars, and the dot annotations for all object instances of a target class are annotated.
is the number of exemplars, and the dot annotations for all object instances of a target class are annotated.
2.1. Feature extraction and feature aggregation
Feature extraction: A CNN backbone is used to extract feature map  from the input image where
from the input image where  are height, width, and number of channels of the feature map, respectively. We then extract the exemplar feature vectors
are height, width, and number of channels of the feature map, respectively. We then extract the exemplar feature vectors  , at the center of the exemplar bounding boxes
, at the center of the exemplar bounding boxes  . Finally, the exemplar feature vector
. Finally, the exemplar feature vector  is obtained by averaging these feature vectors, or
is obtained by averaging these feature vectors, or  .
.
Feature aggregation: We integrate the exemplar feature  to the feature map of the image
to the feature map of the image  to produce the exemplar-integrated feature map
to produce the exemplar-integrated feature map  :
:
(1) ![\begin{equation*} F^A = W_{proj} * [F^I; F^I\otimes f^B] \end{equation*}](https://research.vinai.io/wp-content/ql-cache/quicklatex.com-3135b10bc377fb8d36084e5b53dec66c_l3.svg "Rendered by QuickLaTeX.com")
where ![*, \otimes, [\cdot;\cdot]](https://research.vinai.io/wp-content/ql-cache/quicklatex.com-08c5f2dcdfbc6c0c095664bd51579a55_l3.svg "Rendered by QuickLaTeX.com") are the convolution, channel-wise multiplication, and concatenation operations, respectively.
are the convolution, channel-wise multiplication, and concatenation operations, respectively.  is a linear projection weight.
is a linear projection weight.
2.2. The encoder-decoder Transformer
Inspired by DETR [1], we design our transformer of Counting-DETR to take as input the exemplar-integrated feature map and  query points
query points  and predict the bounding box bm for each query point pm. The queries are the 2D points representing the initial guesses for the object locations rather than the learnable embeddings to achieve a faster training rate as shown in [8].
and predict the bounding box bm for each query point pm. The queries are the 2D points representing the initial guesses for the object locations rather than the learnable embeddings to achieve a faster training rate as shown in [8].
Next, the decoder is used to: (1) predict the classification score s representing the presence or absence of the object at a particular location, (2) regress the object’s bounding box µ represented by the offset  from the GT object center to the query point along with its size
from the GT object center to the query point along with its size  . Following [8], first, the Hungarian algorithm is used to match each of the GT bounding boxes with its corresponding predicted bounding boxes. Then for each pair of matched GT and predicted bounding boxes, the focal loss [5] and the combination of L1 loss and GIoU loss [7] are used as training loss functions. In particular, at each query point, the following loss is computed:
. Following [8], first, the Hungarian algorithm is used to match each of the GT bounding boxes with its corresponding predicted bounding boxes. Then for each pair of matched GT and predicted bounding boxes, the focal loss [5] and the combination of L1 loss and GIoU loss [7] are used as training loss functions. In particular, at each query point, the following loss is computed:
(2) 
Where  are the GT class label and bounding box, respectively.
are the GT class label and bounding box, respectively.  are the coefficients of focal, L1, and GIoU loss functions, respectively.
are the coefficients of focal, L1, and GIoU loss functions, respectively.
Counting-DETR also estimates the uncertainty  when training under the supervision of the imperfect pseudo GT bounding boxes
when training under the supervision of the imperfect pseudo GT bounding boxes  . This uncertainty is used to regularize the learning of bounding box
. This uncertainty is used to regularize the learning of bounding box  such that a lower loss is incurred at the prediction with high uncertainty:
such that a lower loss is incurred at the prediction with high uncertainty:
(3) 
2.3. Two-stage training strategy
We propose a two-stage training strategy as follows. In Stage 1, we first pretrain Counting-DETR on a few exemplar bounding boxes with their centers as the query points (as described in Sec. 3.2). Subsequently, the pretrained network is used to predict the pseudo GT bounding boxes on the training images with the dot annotations as the query points.
In Stage 2, the generated pseudo GT bounding boxes on the training images are used to fine-tune the pretrained Counting-DETR. The fine-tuned model is then used to make predictions on the test images with the uniformly sampled anchor points as queries. Different from Stage 1, the supervision is the imperfect pseudo GT bounding boxes, hence, we additionally leverage the uncertainty estimation branch with uncertainty loss to train. Particularly, we use the following loss to train Counting-DETR in this stage:
(4) 
3. New datasets for Few-shot Counting and Detection
3.1. FSCD-147 dataset
The FSC-147 dataset [6] was recently introduced for the few-shot object counting task with 6135 images across a diverse set of 147 object categories. In each image, the dot annotation for all objects and three exemplar boxes are provided. However, this dataset does not contain bounding box annotations for all objects. For evaluation purposes, we extend the FSC-147 dataset by providing bounding box annotations for all objects of the val and test sets. We name the new dataset FSCD-147.
3.2. The FSCD-LVIS dataset
For real-world deployment of methods for few-shot counting and detection, we introduce a new dataset called FSCD-LVIS. Specifically, the scene is more complex with multiple object classes with multiple object instances each. The FSCD-LVIS dataset contains 6196 images and 377 classes, extracted from the LVIS dataset [4]. The LVIS dataset has the box annotations for all objects, however, to be consistent with the setting of FSCD, we randomly choose three annotated bounding boxes of a selected object class as the exemplars for each image in the training set of FSCD-LVIS.

Figure 4: Sample images from our datasets and annotated bounding boxes.
4. Experimental Results
4.1. Ablation study
Pseudo box and uncertainty loss:
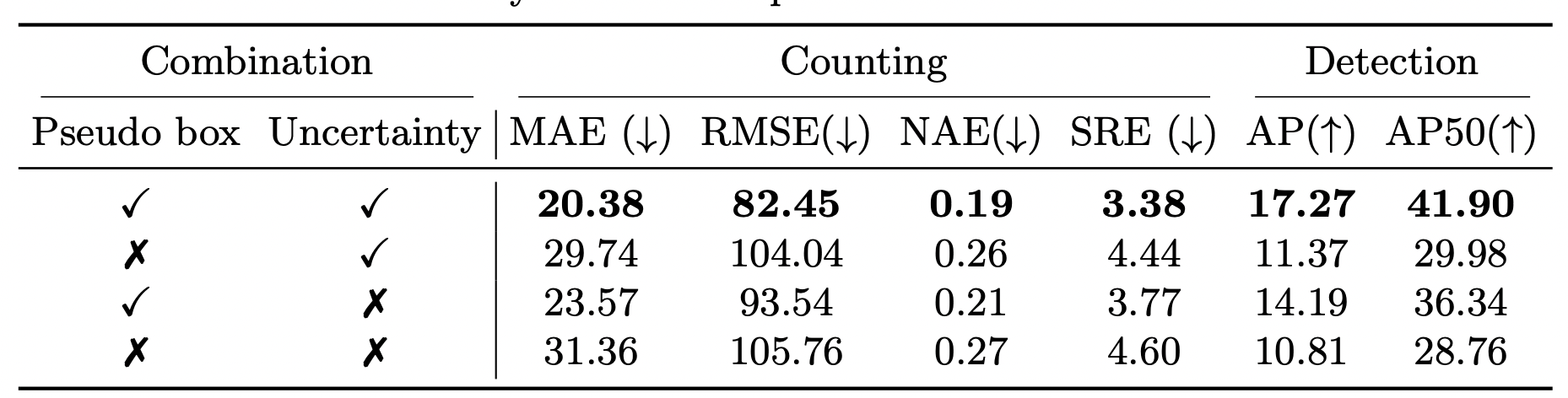
Table 1: Ablation study on each component’s contribution to the final results
Types of anchor points:
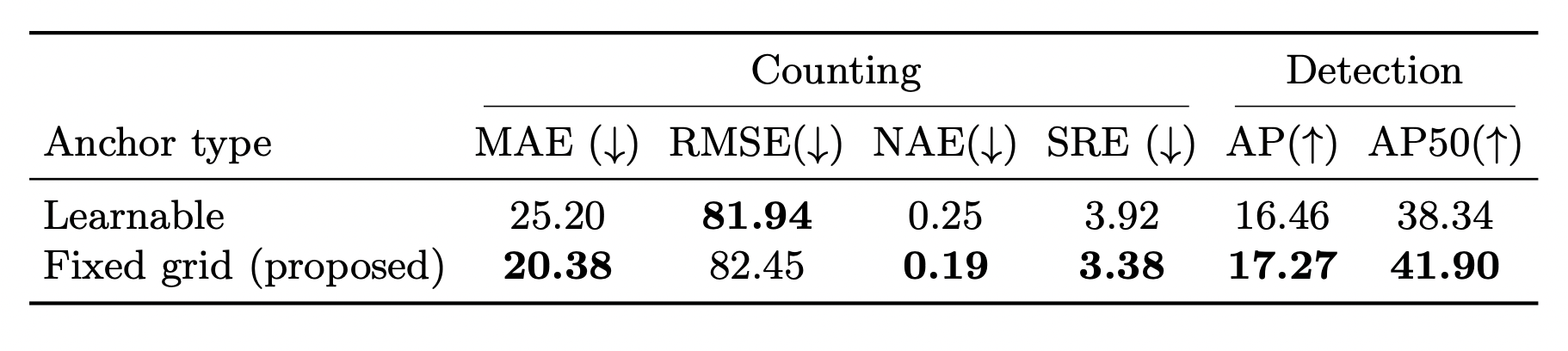
Table 2: Ablation study on types of anchor points
Number of anchor points:
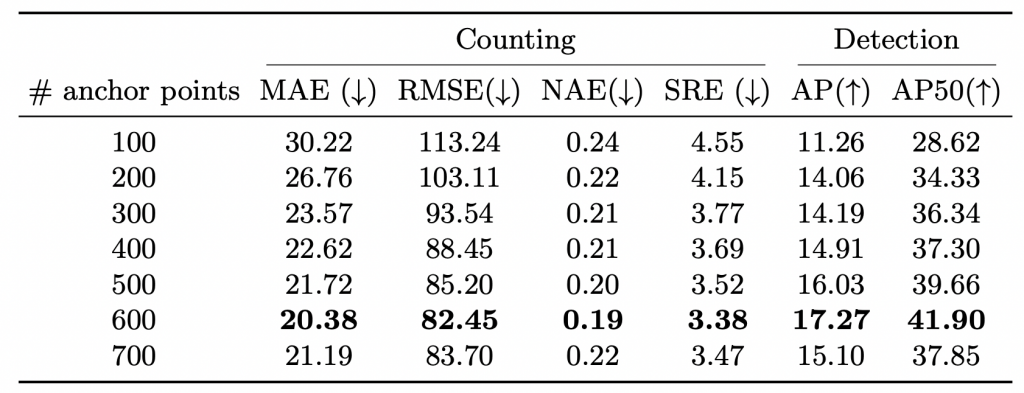
Table 3: Ablation study on number of anchor points
Uncertainty loss:
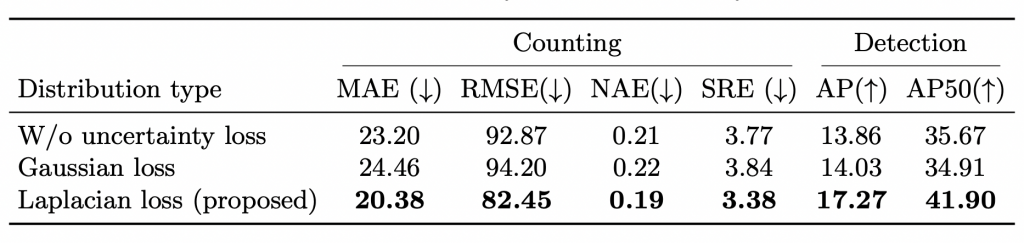
Table 4: Ablation study on uncertainty loss
4.2. Main Results
Comparison with strong baselines on FSCD-147:
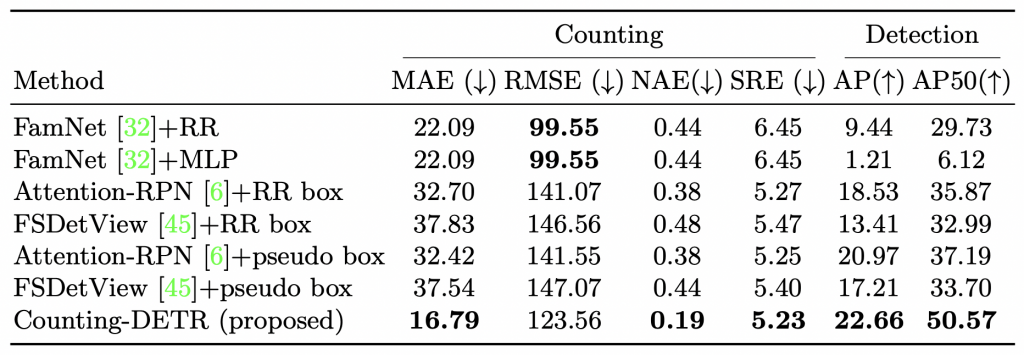
Table 5: Comparison with baselines on FSCD-147
Comparison with strong baselines on FSCD-LVIS:
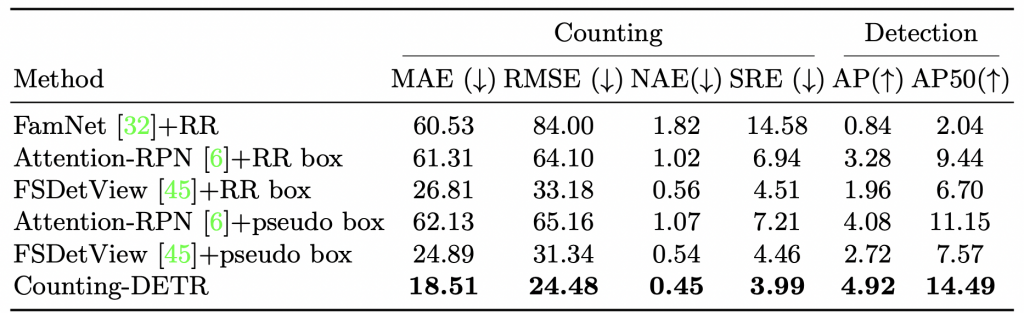
Table 6: Comparison with baselines on FSCD-LVIS
Qualitative Results:
Fig.5 shows the qualitative comparison between our approach and the other methods, including FSDetView [9], Attention-RPN [3], and FamNet [6]+RR. Our method can successfully detect the objects of interest while other methods cannot, as shown in the first four rows of Fig.5. The last row is a failure case for all methods, due to object truncation, perspective distortion, and scale variation.

Figure 5: Qualitative Results on FSCD-147 dataset
References:
1. Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European conference on computer vision (ECCV). Springer (2020) 3
2. Chen, L., Yang, T., Zhang, X., Zhang, W., Sun, J.: Points as queries: Weakly semi-supervised object detection by points. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8823–8832 (2021) 2
3. Fan, Q., Zhuo, W., Tang, C.K., Tai, Y.W.: Few-shot object detection with attention-
rpn and multi-relation detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020) 6, 7
4. Gupta, A., Dollar, P., Girshick, R.: Lvis: A dataset for large vocabulary instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) (2019) 5
5. Lin, T.Y., Goyal, P., Girshick, R., He, K., Doll ́ar, P.: Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision (ICCV) (2017) 4
6. Ranjan, V., Sharma, U., Nguyen, T., Hoai, M.: Learning to count everything. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021) 1, 4, 6, 7
7. Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., Savarese, S.: Generalized intersection over union: A metric and a loss for bounding box regression. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 658–666 (2019) 4
8. Wang, Y., Zhang, X., Yang, T., Sun, J.: Anchor detr: Query design for transfomer based detector. arXiv preprint arXiv:2109.07107 (2021) 4
9. Xiao, Y., Marlet, R.: Few-shot object detection and viewpoint estimation for objects in the wild. In: European Conference on Computer Vision (ECCV). Springer (2020) 6, 7



