BERTweet: The first large-scale pre-trained language model for English Tweets
July 7, 2020
Motivations:
The language model BERT—the Bidirectional Encoder Representations from Transformers—and its variants have successfully helped produce new state-of-the-art performance results for various NLP tasks. Their success has largely covered the common English domains such as Wikipedia, news and books. For specific domains such as biomedical or scientific, we could train domain-specific models using the BERT architecture, such as SciBERT and BioBERT.
Twitter has been one of the most popular micro-blogging platforms where users can share real-time information related to all kinds of topics and events. The enormous and plentiful Tweet data has been proven to be a widely used and real-time source of information in various important analytic tasks. It is worth noting that the characteristics of Tweets are generally different from those of traditional written text such as Wikipedia and news articles, due to the typical short length of Tweets and frequent use of informal grammar as well as irregular vocabulary e.g. abbreviations, typographical errors and hashtags. Thus, this might lead to a challenge in applying existing language models pre-trained on large-scale conventional text corpora with formal grammar and regular vocabulary to handle text analytic tasks on Tweet data. However, to the best of our knowledge, there is not an existing language model pre-trained on a large-scale corpus of English Tweets.
How we handle this gap:
To fill the gap, we train the first large-scale language model for English Tweets, which we name as BERTweet, using a 80GB corpus of 850M English Tweets. In particular, this dataset is a concatenation of two corpora:
We first download the general Twitter Stream grabbed by the Archive Team, containing 4TB of Tweet data streamed from 01/2012 to 08/2019 on Twitter. To identify English Tweets, we employ the language identification component of fastText. We tokenize those Tweets using “TweetTokenizer” from the NLTK toolkit and use the emoji package to translate emotion icons into text strings (here, each icon is referred to as a word token). We also normalize the Tweets by converting user mentions and web/url links into special tokens @USER and HTTPURL, respectively. We filter out retweeted Tweets and the ones shorter than 10 or longer than 64 word tokens. This process results in the first corpus of 845M English Tweets.
We also stream Tweets related to the COVID-19 pandemic, available from 01/2020 to 03/2020. We apply the same data processing step as described above, thus resulting in the second corpus of 5M English Tweets.
Our BERTweet uses the same architecture configuration as BERT-base, which is trained with a masked language modeling objective. BERTweet pre-training procedure is based on RoBERTa which optimizes the BERT pre-training approach for more robust performance. We train BERTweet with 40 epochs for about 4 weeks, using 8 Nvidia V100 GPUs (32GB each). Figure 1 illustrates how our BERTweet predicts a masked token given a contextual sentence where the masked token appears.
Figure 1: Illustration of using BERTweet for filling masks. The number at the end of each row represents the probability of predicting the corresponding candidate.
How we evaluate BERTweet:
We evaluate and compare the performance of BERTweet with strong baselines on three downstream NLP tasks of POS tagging, NER and text classification, using benchmark Tweet datasets.
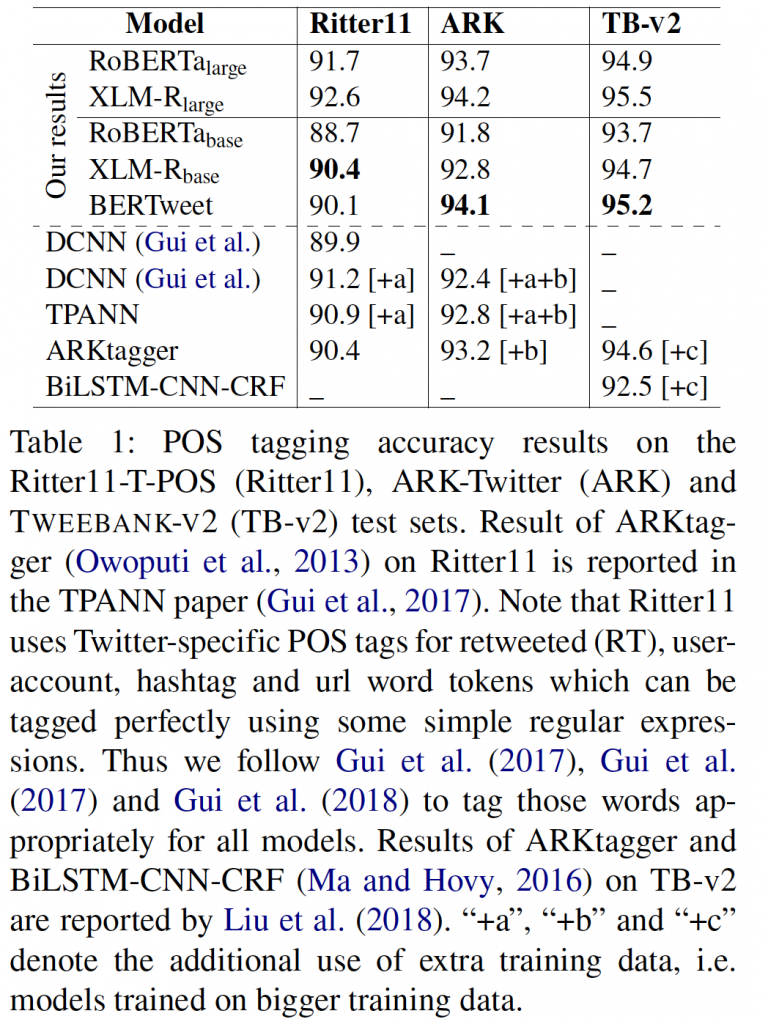
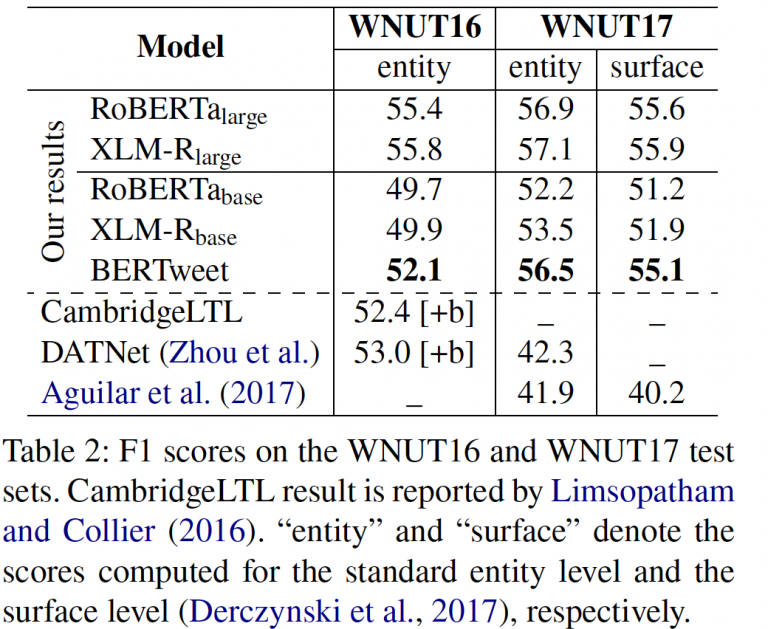
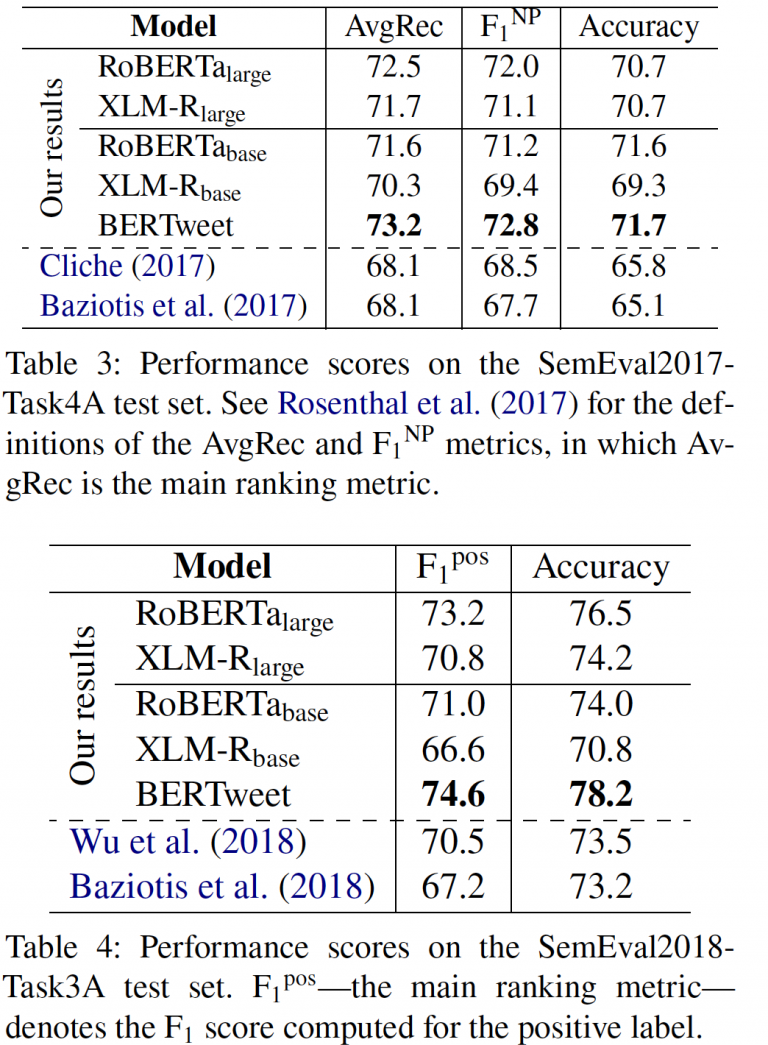
Tables 1, 2, 3 and 4 present our obtained scores for BERTweet and baselines. Our BERTweet outperforms its main competitors RoBERTa-base and XLM-R-base on all experimental datasets (with only one exception that XLM-R-base does slightly better than BERTweet on Ritter11-T-POS). Compared to RoBERTa-large and XLMR-large which use significantly larger model configurations, we find that they obtain better POS tagging and NER scores than BERTweet. However, BERTweet performs better than those large models on the two text classification datasets SemEval2017-Task4A and SemEval2018-Task3A.
Tables 1, 2, 3 and 4 also compare our obtained scores with the previous highest reported results on the same test sets. Clearly, the pre-trained language models help achieve new SOTA results on all experimental datasets. Specifically, BERTweet improves the previous SOTA in the novel and emerging entity recognition by absolute 14+% on the WNUT17 dataset, and in text classification by 5% and 4% on the SemEval2017-Task4A and SemEval2018-Task3A test sets, respectively. Our results confirm the effectiveness of our large-scale BERTweet for Tweet NLP.
We also note that although RoBERTa and XLM-R use 160 / 80 = 2 times and 301 / 80 = 3.75 times bigger English data than our BERTweet, respectively, BERTweet does better than its competitors RoBERTa-base and XLM-R-base. Thus, this confirms the effectiveness of a large-scale and domain-specific pre-trained language model for English Tweets. In future work, we will release a “large” version of BERTweet, which likely performs better than RoBERTa-large and XLM-R-large on all three evaluation tasks.
Why it matters:
We present the first large-scale pre-trained language model for English Tweets. Our model does better than its competitors RoBERTa-base and XLM-R-base and outperforms previous SOTA models on three downstream Tweet NLP tasks of POS tagging, NER and text classification, thus confirming the effectiveness of the large-scale and domain-specific language model pre-trained for English Tweets. We publicly release our model under the name BERTweet which can be used with fairseq and transformers. We hope that BERTweet can serve as a strong baseline for future research and applications of Tweet analytic tasks.