PhoMT: A High-Quality and Large-Scale Benchmark Dataset for Vietnamese-English Machine Translation
December 20, 2021
Motivation
Vietnam has achieved rapid economic growth in the last two decades. It is now an attractive destination for trade and investment. Due to the language barrier, foreigners usually rely on automatic machine translation (MT) systems to translate Vietnamese texts into their native language or another language they are familiar with, e.g. the global language English, so they could quickly catch up with ongoing events in Vietnam. Thus the demand for high-quality Vietnamese-English MT has rapidly increased. However, state-of-the-art MT models require high-quality and large-scale corpora for training to be able to reach near human-level translation quality. Despite being one of the most spoken languages in the world with about 100M speakers, Vietnamese is referred to as a low-resource language in MT research because publicly available parallel corpora for Vietnamese in general and in particular for Vietnamese-English MT are not large enough or have low-quality translation pairs, including those with different sentence meanings (i.e. misalignment).
Our contributions
We present PhoMT, a high-quality and large-scale Vietnamese-English parallel dataset, consisting of 3.02M sentence pairs.
We empirically investigate strong neural MT baselines on our dataset and compare them with well-known automatic translation engines.
We publicly release our PhoMT dataset for research or educational purposes.
PhoMT dataset
Our dataset construction process consists of 4 phases.
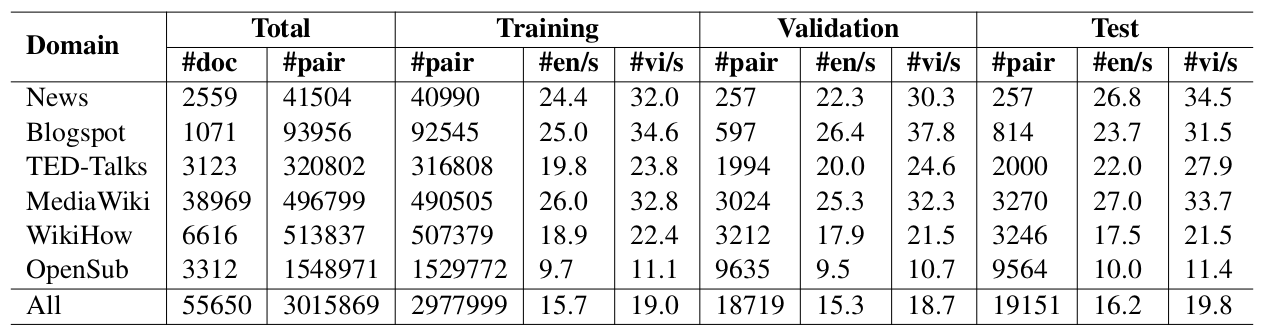
We collect the parallel document pairs from publicly available resources on the Internet, divided into 6 domains: News, Blogspot, TED-Talks, Mediawiki, WikiHow and OpenSubtitles.
In the 2nd phase, we pre-process raw documents to produce cleaned and high-quality parallel document pairs and then extract sentences from these pairs.
The 3rd phase is to align parallel sentences within a pair of parallel documents. We translate English source sentences into Vietnamese by using Google Translate, then perform alignment using 3 popular toolkits: Hunalign, Gargantua, Bleualign.
Finally, we filter out duplicate parallel sentence pairs and manually verify the quality of validation and test sets.
Table 1: Our dataset statistics. “#doc”, “#pair”, “#en/s” and “#vi/s” denote the number of parallel document pairs, the number of aligned parallel sentence pairs, the average number of word tokens per English sentence and the average number of syllable tokens per Vietnamese sentence, respectively. “OpenSub” abbreviates OpenSubtitles.
How we evaluate
Our main goals are to:
Perform a comparison between automatic translation engines and strong neural MT baselines.
Demonstrate the usefulness of pre-trained sequence-to-sequence denoising auto-encoder mBART in MT task.
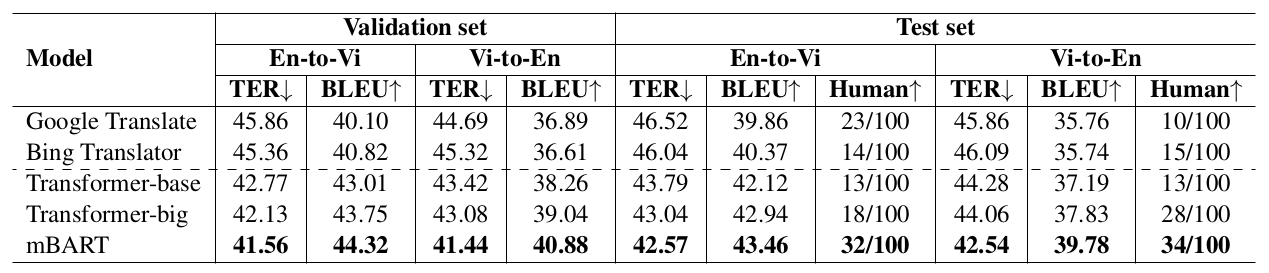
Table 2: Overall results. Each TER/BLEU score difference between two models is statistically significant (p-value <
We find that:
In each setting, mBART achieves the best performance among all models on all metrics, reconfirming the quantitative effectiveness of multilingual denoising pre-training for the neural MT task.
Neural MT baselines can outperform automatic translation engines, which might be explained as the available engines are not fine-tuned on our dataset and thus give a lower result.
However, note that the results on automatic metrics are not always correlated to human evaluations. For example, in the English-to-Vietnamese setup, although Transformer models have +2 points better in TER and BLEU than Google Translate, they are less preferred by humans.
Conclusion
We have presented PhoMT—a high-quality and large-scale Vietnamese-English parallel dataset of 3.02M sentence pairs. We empirically conduct experiments on our PhoMT dataset to compare strong baselines and demonstrate the effectiveness of the pre-trained denoising auto-encoder mBART for neural MT in both automatic and human evaluations. We hope that the public release of our dataset can serve as the starting point for further Vietnamese-English MT research and applications.