Motivations
Vietnamese natural language processing (NLP) research has been significantly explored recently. It has been boosted by the success of the national project on Vietnamese language and speech processing (VLSP) and VLSP workshops that have run shared tasks since 2013. Fundamental tasks of POS tagging, NER and dependency parsing thus play important roles, providing useful features for many downstream application tasks such as machine translation, sentiment analysis, relation extraction, semantic parsing, open information extraction and question answering. Thus, there is a need to develop an NLP toolkit for linguistic annotations w.r.t. Vietnamese POS tagging, NER and dependency parsing. Jointly multi-task learning is a promising approach to develop such a toolkit as it might help reduce the storage space. In addition, POS tagging, NER and dependency parsing are related tasks: POS tags are essential input features used for dependency parsing and POS tags are also used as additional features for NER. Jointly multi-task learning thus might also help improve the performance results against the single-task learning.
How we handle this gap
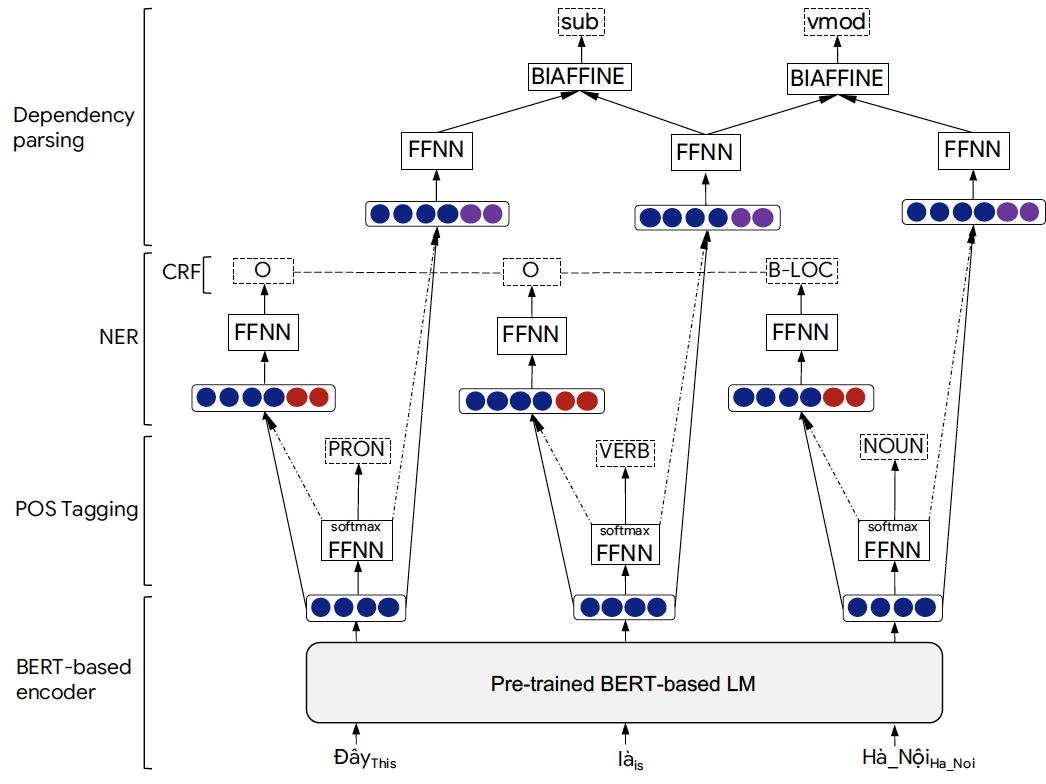
We present a new multi-task learning model, named PhoNLP, for joint POS tagging, NER and dependency parsing. In particular, given an input sentence of words to PhoNLP, an encoding layer generates contextualized word embeddings that represent the input words. These contextualized word embeddings are fed into a POS tagging layer that is in fact a linear prediction layer to predict POS tags for the corresponding input words. Each predicted POS tag is then represented by two “soft” embeddings that are later fed into NER and dependency parsing layers separately. More specifically, based on both the contextualized word embeddings and the “soft” POS tag embeddings, the NER layer uses a linear-chain CRF predictor to predict NER labels for the input words, while the dependency parsing layer uses a Biaffine classifier to predict dependency arcs between the words and another Biaffine classifier to label the predicted arcs.
How we evaluate PhoNLP
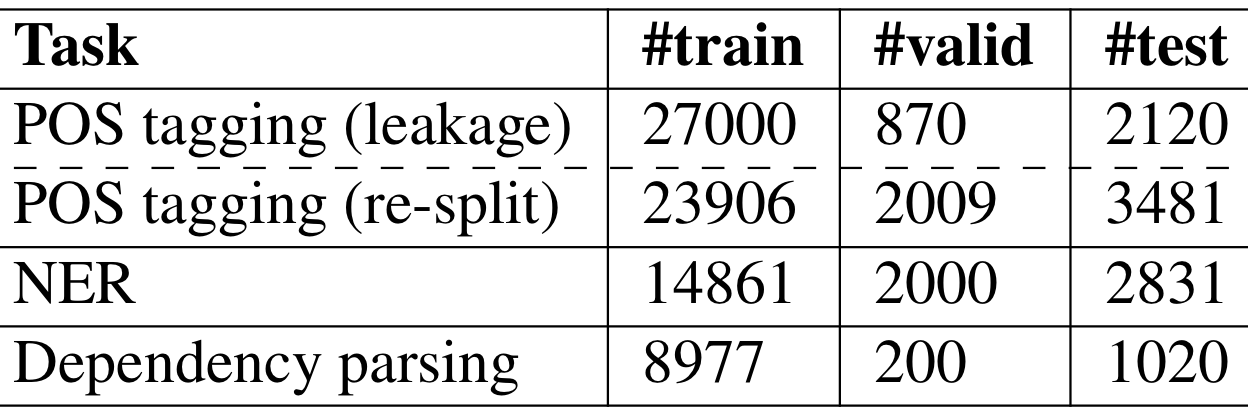
Datasets: To conduct experiments, we use the benchmark datasets of the VLSP 2013 POS tagging dataset, the VLSP 2016 NER dataset and the VnDT dependency treebank v1.1, following the setup used by the VnCoreNLP toolkit. We further discover an issue of data leakage, that has not yet been pointed out before. We thus have to re-split the VLSP 2013 POS tagging dataset to avoid this data leakage issue.
Main results:
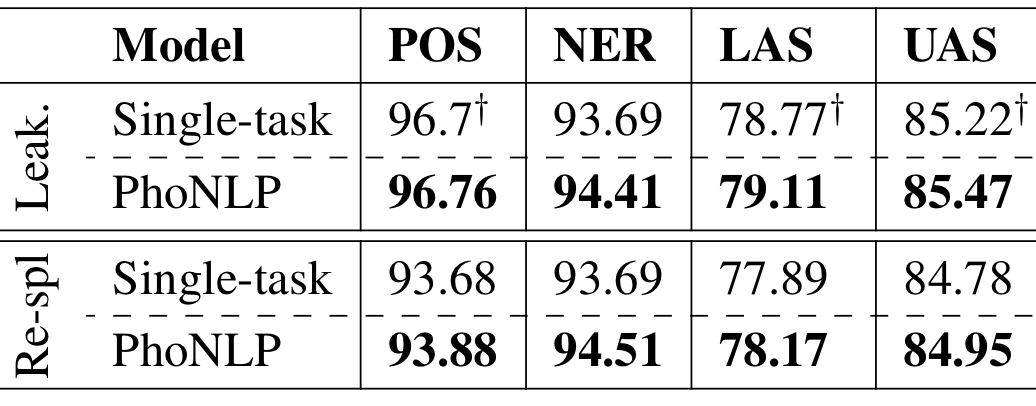
We compare our PhoNLP with a PhoBERT-based baseline approach of single-task training. Our “Single-task” results regarding “Re-split” (i.e. the data re-split and duplication removal for POS tagging to avoid the data leakage issue) can be viewed as new PhoBERT results for a proper experimental setup. We find that in both setups “Leakage” and “Re-split”, our joint multi-task training approach PhoNLP performs better than the PhoBERT-based single-task training approach, thus resulting in state-of-the-art performances for the three tasks of Vietnamese POS tagging, NER and dependency parsing.
Why it matters
We have presented the first multi-task learning model PhoNLP for joint POS tagging, NER and dependency parsing in Vietnamese. Experiments on Vietnamese benchmark datasets show that PhoNLP outperforms its strong fine-tuned PhoBERT-based single-task training baseline, producing state-of-the-art performance results. We publicly release PhoNLP as an easy-to-use open-source toolkit and hope that PhoNLP can facilitate future NLP research and applications. In future work, we will also apply PhoNLP to other languages.