PhoBERT: The first public large-scale language models for Vietnamese
July 7, 2020
Motivations:
Pre-trained language models, especially BERT—the Bidirectional Encoder Representations from Transformers, have recently become extremely popular and helped to produce significant improvement gains in various natural language processing (NLP) tasks. Here, BERT represents word tokens by embedding vectors which encode the contexts where the words appear, i.e. contextualized word embeddings. However, the success of pre-trained BERT and its variants has largely been limited to the English language. For other languages, one could retrain a language-specific model using the BERT architecture or employ existing pre-trained multilingual BERT-based models.
For Vietnamese language modeling, there are two main concerns:
The Vietnamese Wikipedia corpus is the data used to train all monolingual BERT-based language models, and it is also included in the pre-training data used in most multilingual language models. It is worth noting that Wikipedia data is not representative of a general language use, and the Vietnamese Wikipedia data is relatively small (1GB in size uncompressed), while pre-trained language models can be significantly improved by using more data.
All publicly released monolingual and multilingual BERT-based models are not aware of the difference between Vietnamese syllables and word tokens (this ambiguity comes from the fact that the white space is also used to separate syllables that constitute words when written in Vietnamese). Therefore, they are pre-trained with syllable-level Vietnamese text data. Intuitively, for word-level Vietnamese NLP tasks, those models pre-trained on syllable-level data might not perform as good as language models pretrained on word-level data.
How we handle the two concerns above:
To solve the first concern, we use a pre-training dataset of 20GB of uncompressed texts after cleaning. This dataset is a combination of two corpora: (i) the first one is the Vietnamese Wikipedia corpus (∼1GB), and (ii) the second corpus (∼19GB) is a subset of a 50GB Vietnamese news corpus after filtering out similar news articles and duplications. To handle the second concern, we employ RDRSegmenter from VnCoreNLP to perform word and sentence segmentation on the pre-training dataset, resulting in ∼145M word-segmented sentences (∼3B word tokens).
Our PhoBERT pre-training approach is based on the recent state-of-the-art (SOTA) RoBERTa which optimizes the BERT pre-training method for more robust performance. We train PhoBERT with two versions, PhoBERT-base and PhoBERT-large, using the same configuration as BERT-base and BERT-large, respectively. We run the training process for 40 epochs, using 4 Nvidia V100 GPUs (16GB each) during 8 weeks in total.
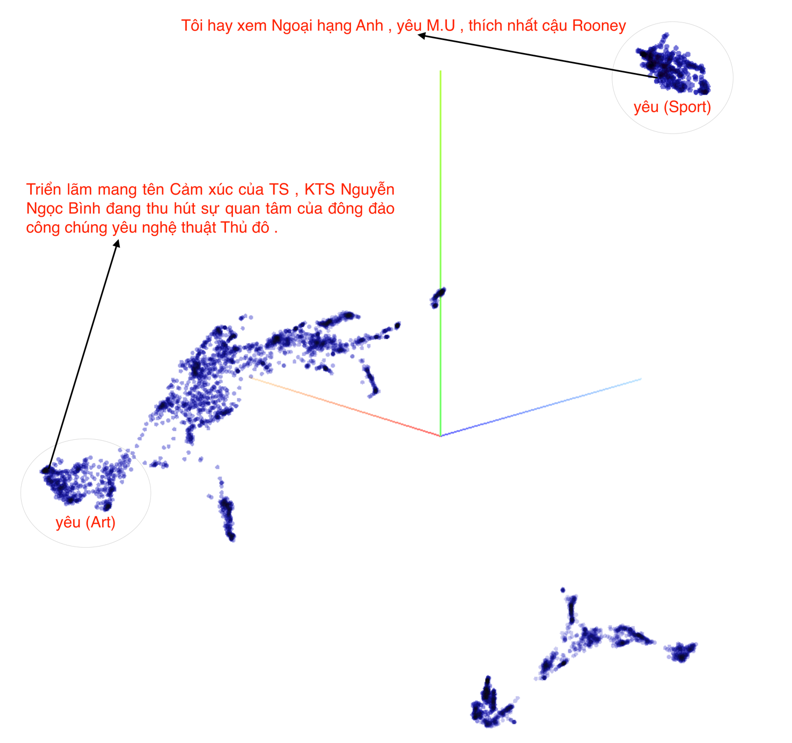
Figure 1. UMAP clusters of 10K PhoBERT-based contextualized word embeddings of word “yêu” (love) from 10K sentences where the word appears (here, Vietnamese word segmentation outputs are not shown for simplification).
Figure 1 illustrates how our PhoBERT-base model generates contextualized word embeddings for the word “yêu” (love) depending on contextual sentences where “yêu” appears. This differs from representing “yêu” by only one embedding vector as in well-known word vector models Word2Vec or GloVe. Clearly, when “yêu” appears in similar contexts then the corresponding contextualized word embeddings are close to each other, while in different contexts we observe significantly different representations of “yêu”.
How we evaluate PhoBERT:
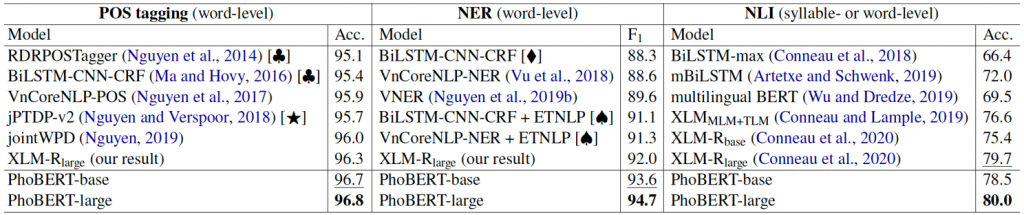
We evaluate our models on three downstream Vietnamese NLP tasks: the two common ones of Part-of-speech (POS) tagging and Named-entity recognition (NER), and a language understanding task of Natural language inference (NLI). Table 1 compares our PhoBERT scores with the previous highest reported results, using the same experimental setup. PhoBERT helps produce new SOTA results for all the three tasks.
Table 1: Performance scores (in %).
Using more pre-training data can significantly improve the quality of the pre-trained language models. Thus, it is not surprising that PhoBERT helps produce better performance than VnCoreNLP-NER trained with BERT-based ETNLP word embeddings on NER, and the multilingual BERT and XLMMLM+TLM on NLI (here, PhoBERT employs 20GB of Vietnamese texts while those models employ the 1GB Vietnamese Wikipedia data).
In addition, we fine-tune the SOTA multilingual XLM-R model for both POS tagging and NER. Table 1 also shows that PhoBERT does better than XLM-R on all three downstream tasks. Note that XLM-R uses a 2.5TB pre-training corpus which contains 137GB of Vietnamese texts (i.e. about 137 / 20 ~ 7 times bigger than our pre-training corpus). Recall that PhoBERT employs word-level data while XLM-R employs syllable-level Vietnamese pre-training data. This reconfirms that dedicated language-specific models still outperform multilingual ones.
Why it matters:
We present the first public large-scale monolingual language models for Vietnamese. Our PhoBERT models help produce the highest performance results for three downstream NLP tasks of POS tagging, NER and NLI, confirming the effectiveness of large-scale BERT-based language models for Vietnamese. We publicly release our PhoBERT to work with popular open source libraries fairseq and transformers, hoping that PhoBERT can serve as a strong baseline for future Vietnamese NLP research and application tasks.