Many-to-Many Voice Conversion based Feature Disentanglement using Variational Autoencoder
September 15, 2021
Motivations
Voice conversion is a challenging task which transforms the voice characteristics of a source speaker to a target speaker without changing linguistic content. Recently, there have been many works on many-to-many Voice Conversion(VC) based on Variational Autoencoder (VAEs) achieving good results, however, these methods lack the ability to disentangle speaker identity and linguistic content to achieve good performance on unseen speaker’s scenarios. In this paper, we propose a new method based on feature disentanglement to tackle many-to-many voice conversions. The method has the capability to disentangle speaker identity and linguistic content from utterances, it can convert from many source speakers to many target speakers with a single autoencoder network. Moreover, it naturally deals with the unseen target speaker’s scenarios. We perform both objective and subjective evaluations to show the competitive performance of our proposed method compared with other state-of-the-art models in terms of naturalness and target speaker similarity.
The Proposed Method
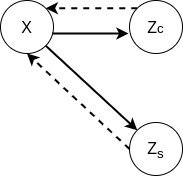
Our final goal is to learn a controllable representation of speech audio from Mel-spectrograms that is useful for converting between two real voice utterances. Therefore, this approach is well-fitted for style transfer, particularly for voice conversion tasks. Our proposed method, which is based on [1], merely relies upon a weak assumption of data to learn disentangled latent space. We hypothesize that for a pair of utterances which come from a speaker, there are some common factors representing speaker information and the remaining factors representing linguistic information as shown in Figure. 1. Technically, speaker identity “Zs” and linguistic content “Zc” are disentangled from a voice utterance.
Figure. 1. Disentanglement VAEs based Voice Conversion. Solid arrows and dash arrows denote inference and generation process, respectively.
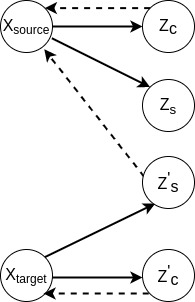
To perform voice conversion, we extract speaker identities and linguistic contents from the source utterance and the target utterance, and then we swap the speaker identity of the target speaker with the speaker identity of the source speaker (see Figure. 2). By doing that, we are able to generate the new utterance which keeps the linguistic content of the source utterance, however, the generated utterance has the similar prosody with the target utterance.
Figure. 2. The voice conversion procedure using Variational Autoencoder. Solid arrows and dash arrows denote inference and generation process, respectively.
Looking at Figure. 3, we illustrate the capability of our proposed method called Disentangled-VAE for prosody conversion. It is clear to see that Disentangled-VAE converts the female utterance “Please call Stella” to a male utterance with the same content.
Female Mel-spectrogram
Male Mel-spectrogram
Figure. 3. The Mel-spectrogram of male and female of the utterance: “Please call Stella”. Our model is capable of converting the original utterance(the female voice) to the target utterance prosody(the male voice).
Empirical Results
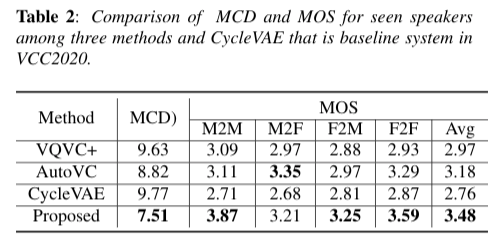
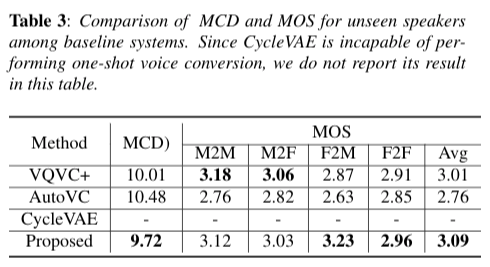
We evaluate the performance of the proposed method through both objective and subjective evaluation compared with three baseline models: Autovc [2], VQVC+ [3], and CycleVAE [4] that is the baseline system for VCC2020 [5]. In both the Tables. 2 and 3, our method significantly outperforms the baseline systems in terms of MCD(Mel-ceptra) and MOS(mean opinion score).
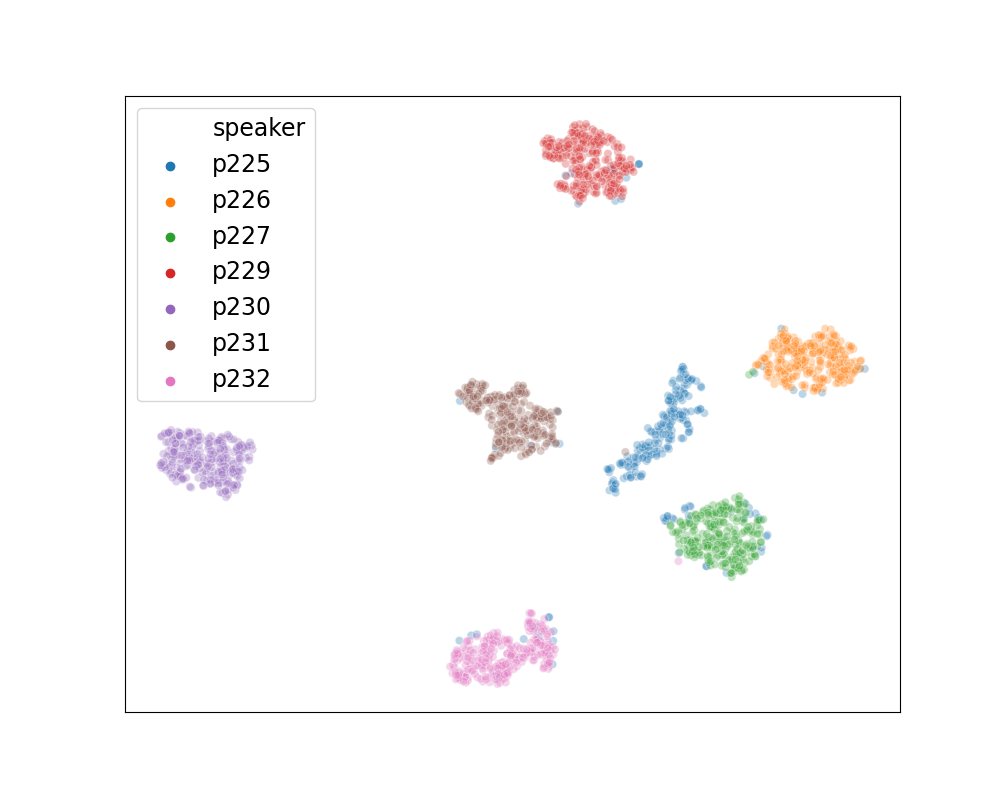
Furthemore, as shown in Figure. 4 The learned speaker embeddings, which stand for speaker identities, are separable from one another if they are from different speakers. Alternatively, they are close to others if they are from the same speaker. This property shows that our model successfully disentangles speaker identity from speech utterances.
Figure. 4. The tSNE visualization of speaker embedding space.
References
F. Locatello, B. Poole, G. R ̈atsch, B. Scholkopf, O. Bachem,and M. Tschannen, “Weakly-supervised disentanglement without compromises,”ArXiv, vol. abs/2002.02886, 2020.
K. Qian, Y. Zhang, S. Chang, X. Yang, and M. Hasegawa-Johnson, “AutoVC: Zero-shot voice style transfer with only autoencoder loss,” ser. Proceedings of Machine Learning Research,K. Chaudhuri and R. Salakhutdinov, Eds., vol. 97.Long Beach,California, USA: PMLR, 09–15 Jun 2019, pp. 5210–5219.
D. Wu, Y.-H. Chen, and H. yi Lee, “VQVC+: One-shot voice con-version by vector quantization and u-net architecture,”ArXiv, vol.abs/2006.04154, 2020.
P. Tobing, Y. Wu, T. Hayashi, K. Kobayashi, and T. Toda, “Non-parallel voice conversion with cyclic variational autoencoder,” in INTERSPEECH, 2019.
P. L. Tobing, Y.-C. Wu, and T. Toda, “Baseline system of voiceconversion challenge 2020 with cyclic variational autoencoderand parallel wavegan,”ArXiv, vol. abs/2010.04429, 2020.