Spoken language understanding (SLU) is a crucial component of task-oriented dialogue systems, which typically handles natural language understanding tasks including intent detection and slot filling. In particular, intent detection aims to identify a speaker’s intent from a given utterance, while slot filling is to extract from the utterance the correct argument value for the slots of the intent. Despite being the 17th most spoken language in the world (about 100M speakers), data resources for Vietnamese SLU are limited. To the best of our knowledge, there is no public Vietnamese dataset available specifically for either intent detection or slot filling.
How we handle this gap
We introduce the first public intent detection and slot filling dataset—named PhoATIS—for Vietnamese.
We propose a joint model—named JointIDSF—for intent detection and slot filling.
Our dataset construction process includes three manual phases. The first phase is to create a raw natural Vietnamese utterance set that is translated based on the ATIS dataset, a popular benchmark for intent detection and slot filling in the flight travel domain. The second phase is to project intent and slot annotations from ATIS to its Vietnamese-translated version. The last one is to fix inconsistencies among projected annotations.
Note that during the translation phase, we require adaptive modifications to make the translated utterances reflect real-world scenarios in the context of airline booking in Vietnam. We also require to preserve spoken modalities (e.g. disfluency, word repetition and collocation) as much as possible to obtain a translated dataset that is correct, natural and similar to the real-world scenarios in Vietnam.
Table 1: Statistics of our Vietnamese dataset PhoATIS with 28 intent labels and 82 slot types.
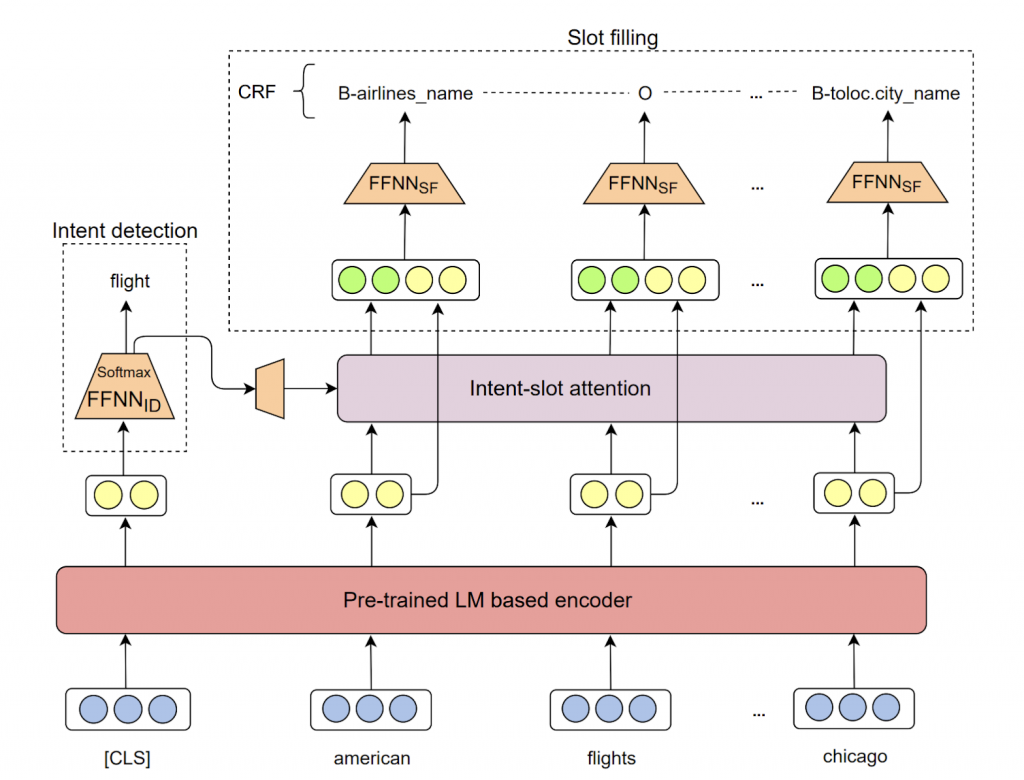
Figure 1: Illustration of our proposed model JointIDSF
Figure 1 illustrates the architecture of our joint model—named JointIDSF—that consists of four layers including: an encoding layer (i.e. encoder) to encode input utterance into contextualized representation; an intermediate intent-slot attention layer to explicitly capture the relationship between intent and slot information; and two decoding layers of intent detection and slot filling to output the corresponding slots and intents labels.
Our JointIDSF can be viewed as an extension of the recent state-of-the-art JointBERT+CRF model, where we introduce the intent-slot attention layer to explicitly incorporate intent context information into slot filling.
The influence of Vietnamese word segmentation (here, input utterances can be formed in either syllable or word level).
The usefulness of pre-trained language model-based encoders. Here, we employ XLM-R and PhoBERT—two recent state-of-the-art pre-trained language models that support Vietnamese—as the encoders.
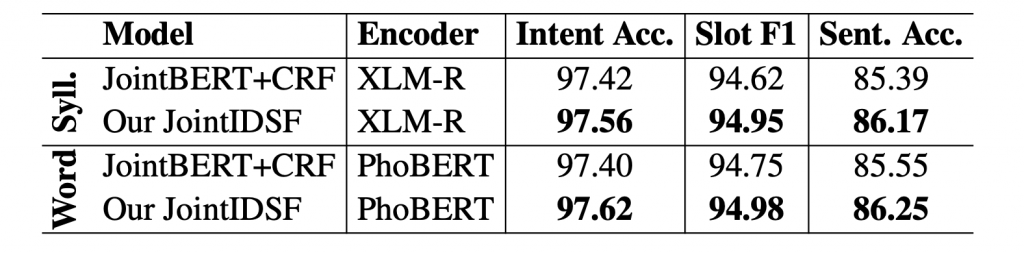
Table 2: Results on the test set. “Intent Acc.” and “Sent.Acc.” denote intent detection accuracy and sentence accuracy, respectively. Each score improvement over JointBERT+CRF with the same encoder is statistically significant with p-value < 0.05 (expect 97.56 vs 97.42 w.r.t. intent accuracy).
We find that:
In each setting, we find that JointIDSF significantly outperforms JointBERT+CRF. Here, the highest improvements are accounted for the sentence accuracy, thus showing that our intent-slot attention layer helps better capture correlations between intent labels and slots in the same utterances.
We also find that the performances of word-level models are higher, but not significantly, than their syllable-level counterparts. Thus, automatic Vietnamese word segmentation and the pre-trained monolingual language model PhoBERT are less effective for these Vietnamese intent detection and slot filling tasks than for other Vietnamese NLP tasks.
A detailed ablation study is also performed to investigate the effectiveness of some variances of the proposed intent-slot attention layer. Please refer to our paper for more information.
Why it matters
Intent detection and slot filling are important tasks in spoken and natural language understanding. However, Vietnamese is a low-resource language in these research topics. In this paper, we present the first public intent detection and slot filling dataset for Vietnamese. In addition, we also propose a joint model for intent detection and slot filling, that extends the recent state-of-the-art JointBERT+CRF model with an intent-slot attention layer to explicitly incorporate intent context information into slot filling via “soft” intent label embedding. Experimental results on our Vietnamese dataset show that our proposed model significantly outperforms JointBERT+CRF.