Introduction
Cross-Lingual Summarization (CLS) is the task of condensing a document of one language into its shorter form in the target language. Most of the contemporary works can be classified into two categories, i.e. low-resourced and high-resourced CLS approaches. In high-resourced scenarios, models are provided with an enormous number of document /summary pairs on which they can be trained [1–3]. On the other hand, in low-resourced settings, those document/summary pairs are scarce, which restrains the amount of information that a model can learn. While high-resourced settings are preferred, in reality, it is difficult to attain a sufficient amount of data, especially for less prevalent languages.
Motivation
Most previous works resolving the issue of little training data concentrate on multi-task learning framework by utilizing the relationship of Cross-Lingual Summarization (CLS) with Monolingual Summarization (MLS) or Neural Machine Translation (NMT). Their approach can be further divided into two groups.
- The first group equips their module with two independent decoders, one of them targets the auxiliary task (MLS or NMT). Nevertheless, since two decoders do not share their parameters, this approach undermines the model’s ability to align between two tasks [4], making the ancillary and the main task less reliant upon each other. Hence, the trained model might produce output that does not match up the topic, or miss important spans of text.
- The second group decides to employ a single decoder dealing with both CLS and MLS tasks. To this end, the method concatenates the monolingual to cross-lingual summary and designate the model to sequentially generate the monolingual summary, and then the cross-lingual one. Unfortunately, this method is not efficacious in capturing the connection between two languages in the output. In that case, the correlation of cross-lingual representations will be tremendously impacted by the structural and morphological similarity of those languages [5]. As a result, in case of summarizing the document from one language to another that possesses distinct morphology and structure properties, such as from Chinese to English, the decoder might be prone to underperformance, due to the dearth of language correlation between two sets of hidden representations in the bilingual vector space [6].
How we resolve the aforementioned problems
To solve the aforementioned problem, we propose a novel Knowledge-Distillation framework for Cross-Lingual Summarization task. Particularly, our framework consists of a teacher model targetting Monolingual Summarization, and a student for Cross-Lingual Summarization.
We initiate our procedure by finetuning the teacher model on monolingual document/summary pairs. Subsequently, we continue to distill summarization knowledge of the trained teacher into the student model. Because the hidden vectors of the teacher and student lie upon two disparate monolingual and cross-lingual spaces, respectively, we propose a Sinkhorn Divergence-based Knowledge Distillation loss, for the distillation process.
Methodology
To resolve the issue of distant languages, the output representations from two vector spaces denoting two languages should be indistinguishable, or easily transported from one space to another. In order to accomplish that goal, we seek to relate the cross-lingual output of the student model to the monolingual output of the teacher model, via utilizing Knowledge Distillation framework and Sinkhorn Divergence calculation. The complete framework is illustrated in Figure 1.
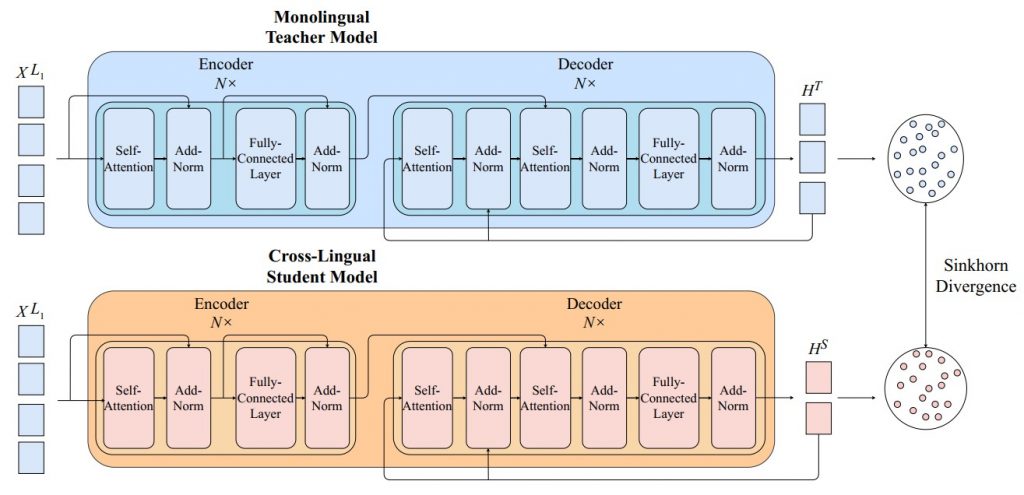
Figure 1: Diagram of Knowledge Distillation Framework for Cross-Lingual Summarization
a) Knowledge Distillation Framework for Cross-Lingual Summarization
We inherit the architecture of Transformer model for our module. In particular, both the teacher and student model uses the encoder-architecture paradigm combined with two fundamental mechanisms. Firstly, the self-attention mechanism will attempt to learn the context of the tokens by attending tokens among each other in the input and output document. Secondly, there is a cross-attention mechanism to correlate the contextualized representations of the output tokens to ones of the input tokens.
In our KD framework, we initiate the process by training the teacher model on the monolingual summarization task. In detail, given an input XL1 = {x1, x2, …, xN}, the teacher model will aim to generate its monolingual summary YL1 = {y1L1, y2L1, …, yML1}. Similar to previous monolingual summarization schemes, our model is trained by maximizing the likelihood of the ground-truth tokens, which takes the cross-entropy form as follows
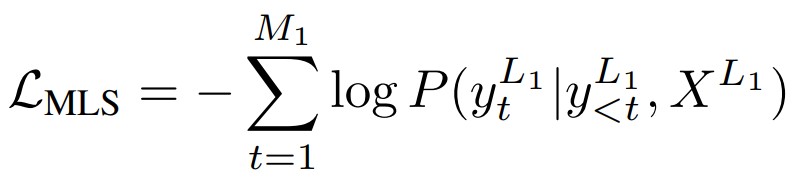
After finetuning the teacher model, we progress to train the student model, which also employs the Transformer architecture. Contrary to the teacher, the student model’s task is to generate the cross-lingual output YL2 = {y1L2, y2L2, …, yML2} in language L2, given the input document XL1 in language L1. We update the parameters of the student model by minimizing the objective function that is formulated as follows
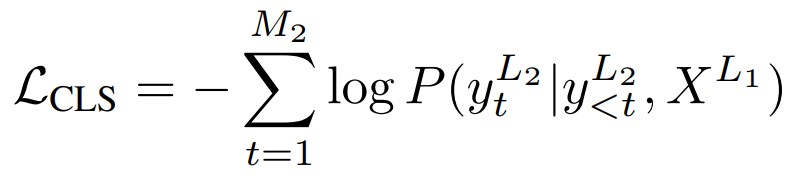
With a view to pulling the cross-lingual and monolingual representations nearer, we implement a KD loss to penalize the large distance of two vector spaces. Particularly, let HT = {h1T, h2T, …, hLTT} denote the contextualized representations produced by the decoder of the teacher model, and HS = {h1S, h2S, …, hLSS} denote the representations from the decoder of the student model, we define our KD loss as follows
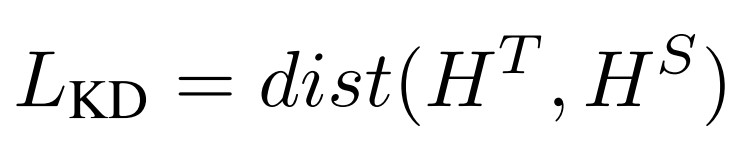
where dist is the Optimal-Transport distance to evaluate the difference of two representations, which we will delineate in the following section.
b) Sinkhorn Divergence for Knowledge Distillation Loss
Due to the dilemma that the hidden representations of the teacher and student model stay upon two disparate vector spaces (as they represent two different languages), we will consider the distance of the two spaces as the distance of two probability measures. To elaborate, we choose to adapt Sinkhorn divergence, a variant of Optimal Transport distance, to calculate the aforementioned spatial discrepancy. Let HT, HS denote the representations of the teacher decoder and the student decoder, we encode the sample measures of them
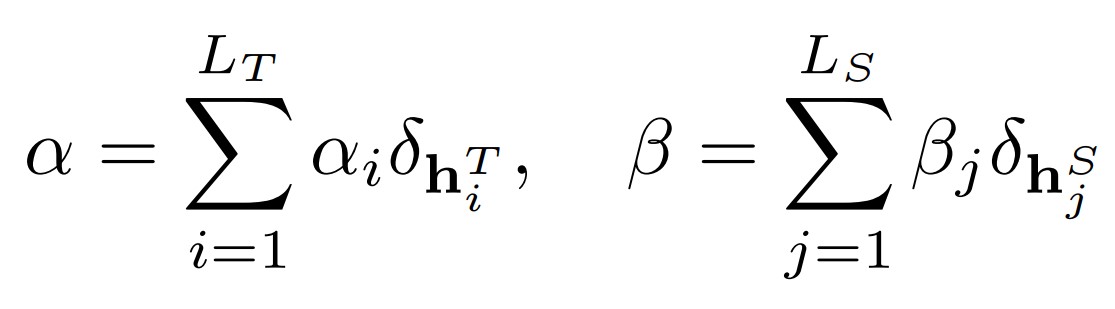
where α and β are probability distributions.
Inspired by (Feydy et al. 2019), we estimate the difference of the representations through determining the Sinkhorn divergence between them
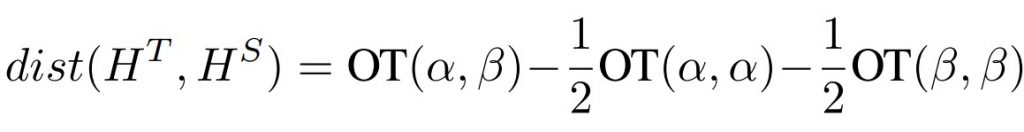
where
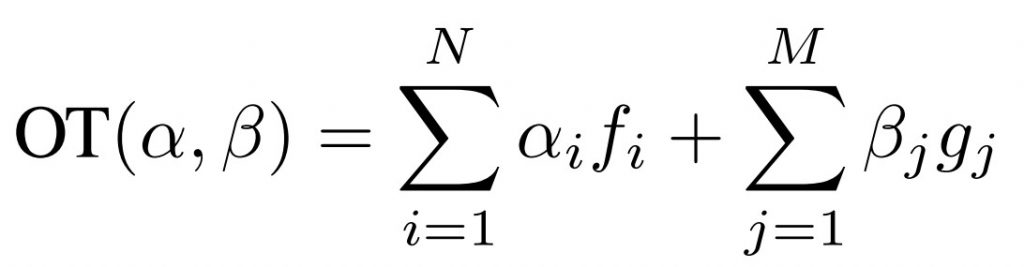
in which fi, gj are estimated by Sinkhorn loop.
c) Training Objective
We amalgamate the Cross-Lingual Summarization and Knowledge Distillation objective to obtain the ultimate objective function. Mathematically, for each input, our training loss is computed as follows
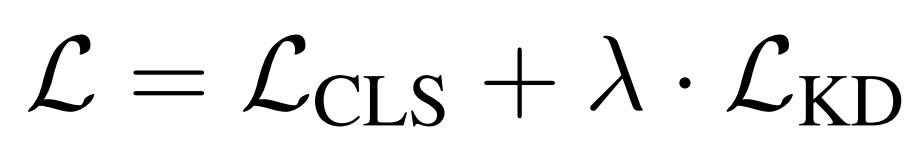
where λ is the hyperparameter that controls the influence of the cross-lingual alignment of two vector spaces.
How we evaluate
We evaluate the effectiveness of our methods on En2Zh and Zh2En datasets processed by [4].
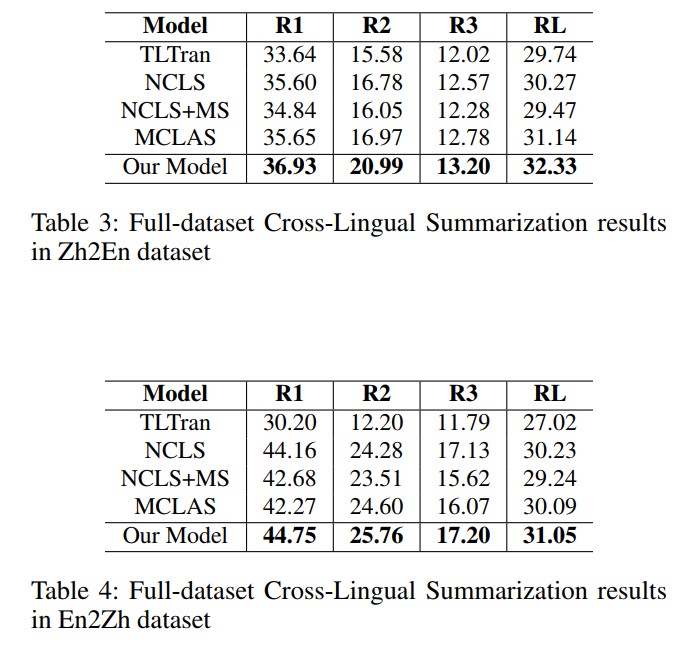
As it can be seen, the above results substantiate our hypothesis that our framework is able to enhance the capability of apprehending and summarizing a document into a summary of another distant language.
Conclusion
In this paper, we propose a novel Knowledge Distillation framework to tackle Neural Cross-Lingual Summarization for morphologically or structurally distant languages. Our framework trains a monolingual teacher model and then finetunes the cross-lingual student model which is distilled knowledge from the aforementioned teacher. Since the hidden representations of the teacher and student model lie upon two different lingual spaces, we continually proposed to adapt Sinkhorn Divergence to efficiently estimate the cross-lingual discrepancy. Extensive experiments show that our method significantly outperforms other approaches under both low-resourced and full-dataset settings.
References
[1] Zhu, J.; Wang, Q.; Wang, Y.; Zhou, Y.; Zhang, J.; Wang, S.; and Zong, C. 2019. NCLS: Neural cross-lingual summarization. arXiv preprint arXiv:1909.00156
[2] Cao, Y.; Liu, H.; and Wan, X. 2020. Jointly Learning to Align and Summarize for Neural Cross-Lingual Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 6220–6231.
[3] Zhu, J.; Zhou, Y.; Zhang, J.; and Zong, C. 2020. Attend, translate and summarize: An efficient method for neural cross-lingual summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 1309–1321.
[4] Bai, Y.; Gao, Y.; and Huang, H. 2021. Cross-Lingual Abstractive Summarization with Limited Parallel Resources. arXiv preprint arXiv:2105.13648.
[5] Bjerva, J.; Ostling, R.; Veiga, M. H.; Tiedemann, J.; and Augenstein, I. 2019. What do language representations really represent? Computational Linguistics, 45(2): 381–389.
[6] Luo, F.; Wang, W.; Liu, J.; Liu, Y.; Bi, B.; Huang, S.; Huang, F.; and Si, L. 2021. VECO: Variable and Flexible Crosslingual Pre-training for Language Understanding and Generation.



