Enriching and Controlling Global Semantics for Text Summarization
September 24, 2021
Introduction
Automatic text summarization corresponds to text understanding and text generation processes. In general, there are two main approaches to perform this task. Extractive systems highlight salient words or sentences from the source text and form the final summary by concatenating them. On the other hand, abstractive methods switch among generating new words, choosing phrases from the source document, and rephrasing them. Abstractive summarization, which is the focus of this work, is usually more advanced and closer to human-like interpretation.
Motivation
Recently, abstractive summarization studies are dominated by Transformer-based architecture. Despite good performance in large scale datasets, Transformer-based summarization models have been proven to have the tendency to favor encoding short-range dependencies, i.e., whenever there is one word from the input generated in the summary, the model tends to continue generating the nearby words due to their high attention scores to the previous generated word. As such, if the main content of the document is out of reach from the generated word, the final summary can miss that key information.
One solution is to furnish the models with global semantics by using probabilistic topic models. Nevertheless, traditional topic models were shown to be inefficient in scalability for large-scale datasets and have limited capability of describing documents.
How do we resolve the problems
To overcome the above problems, we propose a novel method that integrates neural topic model into summarization architecture. Specifically, we aim to utilize the posterior distribution learned from the neural topic model as an approximation of global semantics of the document and from that, provide a signal for summarization model to have a better understanding of overall document. To this end, we propose a method to adapt normalizing flow in the neural topic model to have a better approximation of true distribution and integrate it into the summarization model.
Our Model
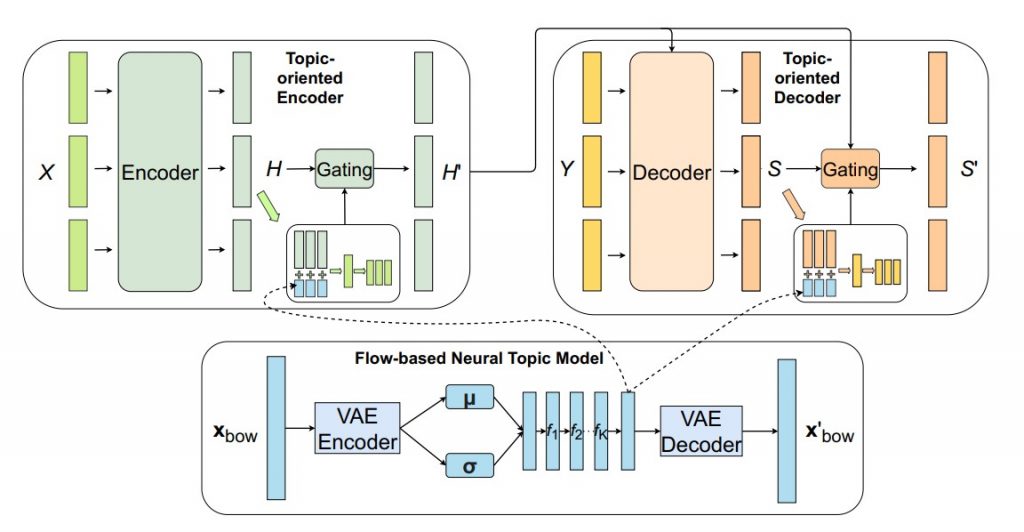
The overall architecture of our approach is given in Figure 1. It comprises of a topic-oriented encoder, a topic-oriented decoder, and a flow-based neural topic model.
Figure 1: Our overall architecture
Experiment Settings
We evaluate our proposed method and compare with erstwhile baselines to verify the effacacy of our approach.
We use the automatic metrics of ROUGE scores, we report the unigram overlap (ROUGE-1), bigram overlap (ROUGE-2) to assess informativeness, and longest common subsequence (ROUGE-L) for the fluency of the generated summary.
Experimental Results
Summarization Quality
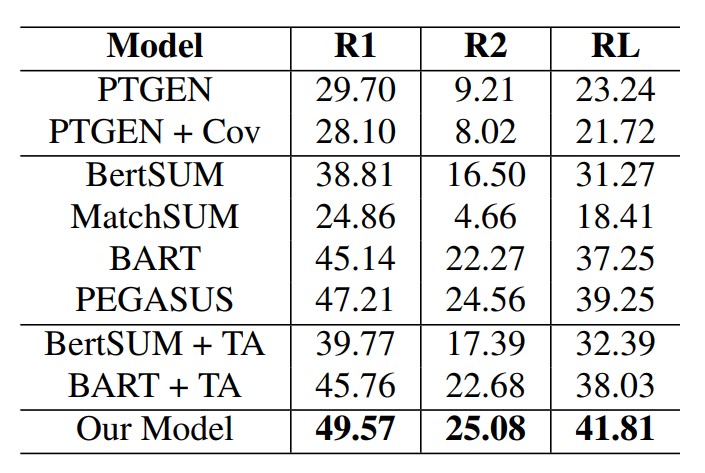
In the experiment, our method significantly outperforms previous approaches. This verifies our hypothesis that global semantics is capable of helping the model generate better target summaries.
Table 1: Results on the test set of our model and baselines. “R1”, “R2”, and “RL” denote ROUGE-1, ROUGE-2, and ROUGE-L scores, respectively. Our method significantly outperforms previous methods in terms of summary quality.
Ablation Study
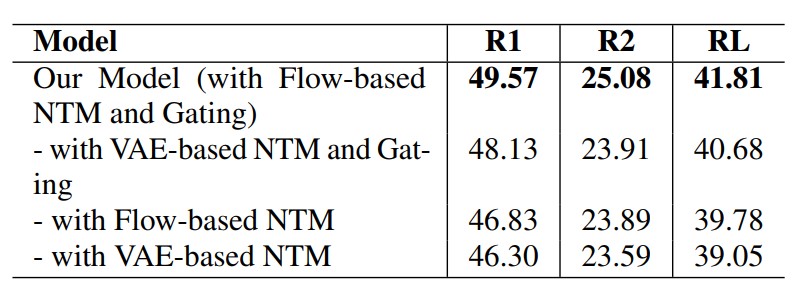
We study the impact that (1) The integration of normalizing flow and (2) The contextualized gating mechanism have on the text summarization performance.
Table 2: Ablation Study on two central constituents of our architecture, Flow-based neural topic model and Gating Mechanism. This verifies superiority of our model over other variances that ignore those two components.
We find that:
Neural topic model packed with normalizing flow produces expressive global semantics that helps to enhance abstractive summarization performance.
Scrupulously incorporating global semantics with gating mechanism reduces superfluity of global semantics, resulting in performance improvement.
For further details such as case studies, please refer to our paper for more information.
Why it matters
Recently, Transformer-based models have been proven effective in the abstractive summarization task by creating fluent and informative summaries. Nevertheless, these models still suffer from the short-range dependency problem, causing them to produce summaries that miss the key points of document. In this paper, we attempt to address this issue by introducing a neural topic model empowered with normalizing flow to capture the global semantics of the document, which are then integrated into the summarization model. In addition, to avoid the overwhelming effect of global semantics on contextualized representation, we introduce a mechanism to control the amount of global semantics supplied to the text generation module. Extensive experiments demonstrate that our method outperforms erstwhile state-of-the-art summarization models.
Reference
Melissa Ailem, Bowen Zhang, and Fei Sha. 2019. Topic augmented generator for abstractive summarization. arXiv preprint arXiv:1908.07026.
Zhengjue Wang, Zhibin Duan, Hao Zhang, Chaojie Wang, Long Tian, Bo Chen, and Mingyuan Zhou. 2020. Friendly topic assistant for transformer based abstractive summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 485–497
Chin-Yew Lin. 2004. Rouge: A package for automaticevaluation of summaries. In Text summarization branches out, pages 74–81